
Par Ben Hunt − Le 25 mars 2020 − Source The Epsilon Theory
 À l’époque, le fonds spéculatif long terme/court terme que je cogérais faisait partie d’un plus grand fonds de gestion d’actifs uniquement à long terme. Leur plus grande stratégie était un fonds de capitalisation de moyenne importance (mid cap $2 à $10 Mds) du marché américain, qui était bien doté en personnel, avec un groupe d’analystes et de chefs de projet très pointus. Mais la société avait également une valeur de 4 Mds de dollars US et la stratégie pour les gros fonds de capitalisation était gérée par au moins deux personnes – le co-fondateur en tant que chef de projet, plus un poste d’analyste qui était une sorte de siège éjectable… les candidats venaient et étaient continuellement éjectés de ce siège.
À l’époque, le fonds spéculatif long terme/court terme que je cogérais faisait partie d’un plus grand fonds de gestion d’actifs uniquement à long terme. Leur plus grande stratégie était un fonds de capitalisation de moyenne importance (mid cap $2 à $10 Mds) du marché américain, qui était bien doté en personnel, avec un groupe d’analystes et de chefs de projet très pointus. Mais la société avait également une valeur de 4 Mds de dollars US et la stratégie pour les gros fonds de capitalisation était gérée par au moins deux personnes – le co-fondateur en tant que chef de projet, plus un poste d’analyste qui était une sorte de siège éjectable… les candidats venaient et étaient continuellement éjectés de ce siège.

Jouez les joueurs, pas les cartes
Le travail de l’analyste solo, pour autant que je sache, consistait essentiellement à aller à des conférences d’investisseurs et à construire d’énormes tableaux Excel pour calculer des modèles de cash flow actualisés pour, par exemple, Google. Et bien sûr, Google serait dans le portefeuille, parce que Google doit être dans un portefeuille de grandes capitalisations, mais cela n’avait rien à voir avec les centaines d’heures de travail nécessaires pour réaliser cette soixantaine de pages de calcul. Je veux dire … si le co-fondateur/chef de projet du fonds d’investissement parlait avec l’analyste plus d’une fois par semaine de quoi que ce soit, c’était une semaine inhabituelle, et il n’y avait aucune chance qu’il ait consulté cette feuille de calcul, ou une autre. Zéro.
Maintenant, pour être clair, je pense que le co-fondateur du fonds était un brillant investisseur. Ce type a réussi… tant en termes de performance de
gestion de portefeuille qu’en terme d’activité de gestion d’actifs. Mais le voilà qui gère un portefeuille de 4 Mds de dollars avec un obscur analyste et ça ne marchait pas du tout. Je lui ai donc parlé un jour et lui ai finalement posé la question suivante : que faites-vous avec les grosses capitalisations ?
Voici sa réponse, et elle m’a collé à la peau depuis.
Écoute, Ben, tu dois comprendre. L’investissement dans les grandes capitalisations…ce n’est pas de la sélection de titres. Je dois faire des recherches et je dois pouvoir parler des noms, parce que c’est ce qu’il y a dans le portefeuille. Mais ce n’est pas de la sélection de titres. Tu vas devenir fou si tu choisis des titres à forte capitalisation, et cela ne te rapportera rien. L’investissement dans les grandes capitalisations est une sélection sectorielle. Ce qui compte, c’est de savoir si je sur-pondère ou sous-pondère un secteur par rapport à l’indice de référence. C’est la seule chose qui compte.
J’ai donc enchaîné la question suivante : comment faire ça ? comment choisir les secteurs d’activité ?
L’argent coule à flots. Je parle aux gars de ce qu’ils voient. Et puis il y a des gars comme Birinyi qui publie chaque mois des montagnes de données sur ce sujet. Vous ne pouvez pas percevoir les petites variations, mais de temps en temps vous pouvez attraper un grand changement dans ou hors d’un secteur d’activité. Et c’est tout ce qu’il faut.
Il m’a montré quelques unes des revues de Laszlo Birinyi. Ils étaient, pour le moins, de style ésotérique, imprimés page après page de cases cochées et de chiffres et de flèches.
Mais j’ai compris.
Il ne se contentait pas de jouer les cartes. Il jouait les joueurs.
Il lisait la bande perforée.
Je sais que ce sera un choc pour presque tous les investisseurs actifs aujourd’hui, mais lire la bande perforée – essayer de capter le flot d’argent qui entre et sort des titres – était la méthode dominante des stratégies d’investissement au moins pendant les années 1960.
L’analyse de la sécurité intrinsèque ? Graham et Dodd ? L’esprit et la sagesse de l’oncle Warren [Buffett, NdT] et le mage d’Omaha ? Toutes ces croyances
et les principes qui sont si chers et sont comme des vérités reçues dans ce monde, le meilleur de tous les mondes possibles ? Pffft. Il y a soixante ans, vous auriez été la risée de Wall Street.
Quoi, vous pensez que nous sommes plus intelligents que ces gars il y a soixante ans ? Vous pensez que nous avons fait une sorte de progrès scientifique qui change la nature sociale des marchés ? Sans rire !

Loeb, co-fondateur de E.F. Hutton, s’est joyeusement penché sur la bande perforée.
Pour un type comme Gerald Loeb, qui a cofondé E.F. Hutton et qui était célèbre pour être du niveau de Warren Buffett à son époque, l’analyse de la valeur intrinsèque d’une action n’était pas seulement mal avisée, elle était carrément destructrice pour la création de richesses. Seuls les ploucs pensaient savoir mieux que le marché ce qu’une action valait, et pendant la Grande Dépression, il a vu ces « investisseurs de valeur » être évincés du terrain par milliers.
Que vaut une action ? Ce que le prochain type est prêt à payer pour l’acquérir, voilà ce qu’elle vaut. Ni plus, ni moins. L’analyse de la sécurité intrinsèque… laissez moi rigoler.
C’est l’évangile de Wall Street de Gerald Loeb. Dans les années 50, tout le monde savait que Gerald Loeb avait raison.
Personne ne se souvient de Gerald Loeb aujourd’hui.

C’était pareil pour Carnegie, Gould, Vanderbilt et tous les autres vieilles gloires de Wall Street, les barons voleurs. Lisez leurs mémoires, ou les mémoires des pauvres types qui ont « investi » contre eux… les barons voleurs n’ont pas construit de modèles de DCF [Discounted Cash Flow, méthode d’actualisation des flux de trésorerie, NdT] ! Ils ont compris la méthode. Ils ont lu la bande perforée et ils l’ont faite. Ils ont compris où l’argent coulait et comment le faire couler là où ils voulaient qu’il coule.
Tous ces types doivent se retourner dans leur tombe en voyant ce que nous sommes devenus – une nation de ploucs, se prosternant et faisant des courbettes devant le grand Dieu de l’analyse de la valeur intrinsèque, achetant au plus haut et vendant au plus bas constamment, tant en politique qu’en investissement, sans autre raison que celle de nous dire que c’est la Vérité avec un V majuscule ici dans le Monde de la Foi.

Marc Benioff l’a compris. Jim Cramer a compris. Ils ont compris le jeu. Pourquoi pas nous ?
Parce que nous sommes de très mauvais joueurs de poker, voilà pourquoi.
Nous regardons les cartes devant nous et nous parions dessus comme si personne dans l’histoire du monde n’avait jamais reçu ces cartes auparavant. Nous parions sans aucune considération stratégique du méta-jeu plus large auquel nous jouons… le jeu des marchés. Nous parions comme si tout ce que nous entendons et voyons des autres joueurs autour de la table, en particulier des joueurs qui ont de très grosses piles de jetons, était la vérité pure et simple, comme si leur gesticulation et les Fiat News – la présentation d’une opinion comme un fait – étaient une sorte d’acte neutre, une sorte de bien public, plutôt que l’acte intentionnel d’auto-valorisation des gens qui veulent nous enlever nos jetons.
Nous pouvons être de meilleurs joueurs de poker.
Pas en mettant 100 heures supplémentaires de travail dans notre tableur DCF sur Google. Pas en faisant plus d’« analyse fondamentale » sur salesforce.com, où … n’oubliez pas ! … La confiance est la valeur la plus élevée ™.
Nous ne pouvons pas être de meilleurs joueurs de poker en jouant les cartes plus agressivement.
Nous pouvons être de meilleurs joueurs de poker en jouant les joueurs beaucoup plus intelligemment.
Nous pouvons être de meilleurs joueurs de poker en appliquant une nouvelle technologie – le traitement du langage naturel (Natural Language Processing) – à une vieille idée – la lecture de la bande perforée.
Nous pouvons être de meilleurs joueurs de poker en anticipant les comportements en matière de flux d’argent grâce à un calcul mathématique de l’effort de propagande que Wall Street fait pour vous DIRE quels secteurs acheter et vous DIRE quels secteurs vendre.

Tout comme Teddy KGB et ses Oreos [personnage du film Rounders (1998), NdT], Wall Street ne peut s’empêcher de signaler ses intentions.
C’est le message littéral de Wall Street.
Je sais… baratin fou. Des images, ou bien ça n’existe pas, c’est ça ? Question légitime.
Depuis quelques années, Epsilon Theory réalise des représentations bidimensionnelles de réseaux de textes de médias financiers, ce que nous appelons des cartes narratives. Nous utilisons une IA en LNP et un logiciel de visualisation de données développé par Quid – une entreprise très cool que vous devriez consulter – pour traiter et représenter les données textuelles. Voici un aperçu en une diapositive de Quid de ce que vous voyez lorsque vous voyez une de ces planches narratives.

Je trouve utile de considérer le logiciel Quid comme un microscope, comme un instrument de laboratoire dont nous pouvons obtenir une licence d’usage. C’est à nous de décider de ce que nous faisons avec ce microscope – comment nous choisissons quelque chose d’approprié à analyser, comment nous préparons les « planches » et comment nous interprétons les résultats.
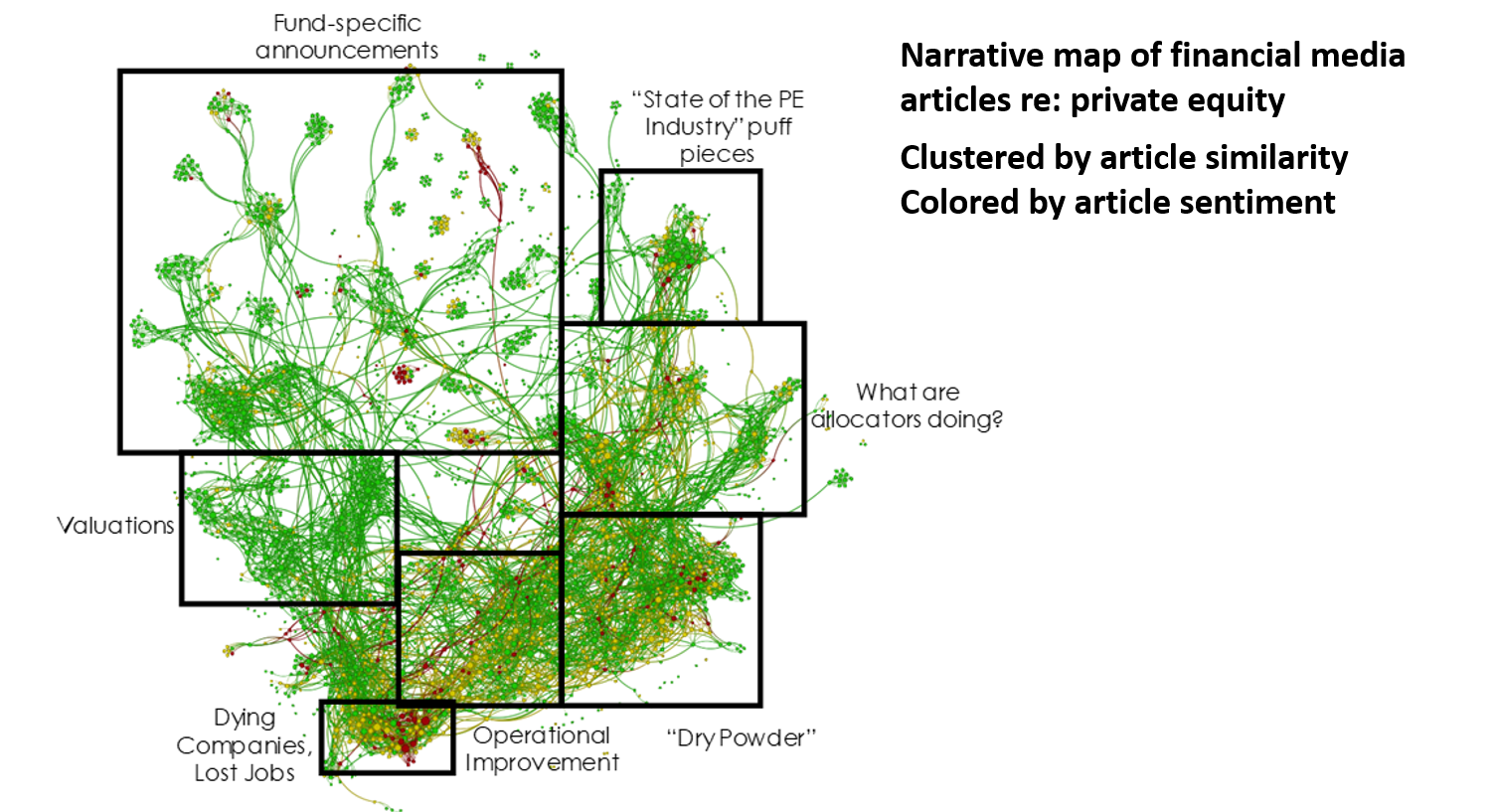
Voici, par exemple, une carte narrative des articles des médias financiers qui contenaient le terme de « actions boursières » au cours des six derniers mois, où chacun des points individuels (nœuds) représente un seul et unique article, où les nœuds sont regroupés par similarités linguistiques, et où les nœuds sont colorés par le score du sentiment général sur chaque article.
Et voici la carte narrative des articles des médias financiers sur la même période qui contenait le terme de recherche « hedge fund ».
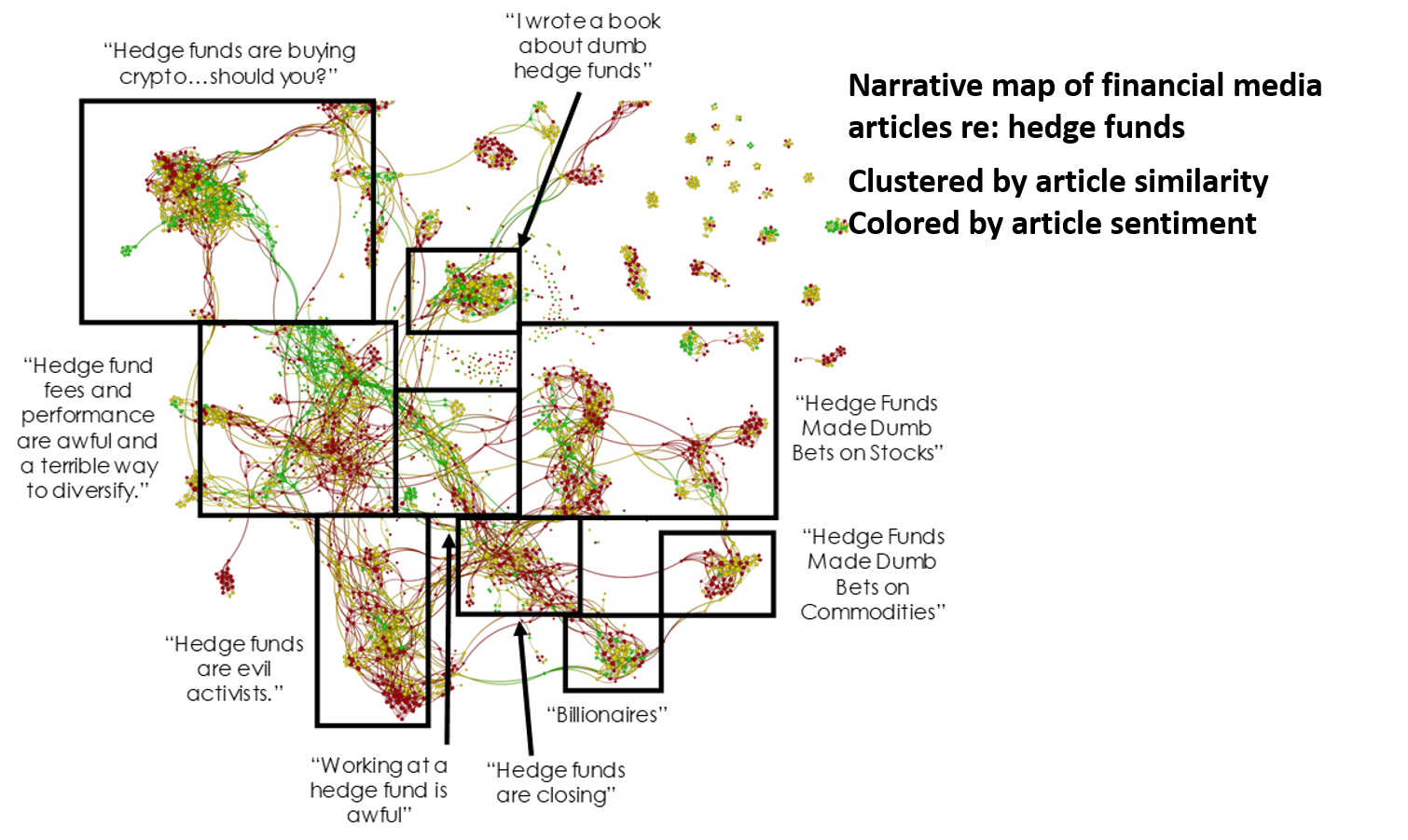
Que signifient les différences entre les deux cartes narratives ? Beaucoup de choses. Selon nous. En d’autres termes, tant que nous examinons ces cartes narratives en deux dimensions et que nous interprétons leurs différences de taille, de forme et de couleur, nous vous donnons notre évaluation qualitative de ces différences. C’est ce que nous pensons, pas ce que nous mesurons, et à moins que les différences soient assez marquées, il peut être difficile pour l’œil humain de faire une différence significative.
De plus – et c’est très important – ces visualisations bidimensionnelles d’une carte narrative compriment nécessairement les données sous-jacentes. Nous perdons des informations lors de la création de cette visualisation, et nous devons descendre au niveau de la matrice de données sous-jacente afin d’utiliser toutes les données et de leur appliquer des maths.
Pour avoir une idée de la matrice de données sous-jacente et des informations que nous pouvons en tirer, nous devons revenir à ce que fait réellement l’IA de toute technologie de traitement du langage naturel (NLP). Une IA en NLP a été formée sur des millions de documents textuels afin de reconnaître la syntaxe et les n-grammes – mots et phrases ayant une signification cachée – dans un ensemble symbolique – une langue. Elle compare chaque n-gramme dans un document textuel avec chaque n-gramme dans un autre document textuel pour créer un ensemble vraiment massif de comparaisons de n-grammes, mis en correspondance avec chaque document.
Supposons que vous ayez 1 000 documents, chacun avec 1 000 n-grammes. Un document de 1 000 n-grammes traité par rapport à un autre document de 1 000 n-grammes génère 1 million de comparaisons n-grammes. Un document traité par rapport à tous les autres documents génère (presque) 1 milliard de comparaisons n-grammes. Un document traité par rapport à un autre document de 1 000 n-grammes génère (presque) 500 milliards de comparaisons n-grammes. C’est un chiffre important, et c’est pourquoi le LNP n’a vraiment pris son essor qu’au cours des quatre ou cinq dernières années … les calculs de données eux-mêmes sont assez triviaux, mais il faut une tonne de puissance de calcul pour effectuer ces tâches en un temps non négligeable.
Organisons maintenant ces comparaisons de n-grammes au niveau du nœud (document), de manière à créer une matrice de chaque nœud par rapport à tous les autres nœuds, avec une profondeur dimensionnelle asymétrique dérivée des n-grammes partagés associés à chaque comparaison de nœud à nœud. Il s’agit d’une matrice comportant des millions de relations entre les nœuds comparés aux n-grammes partagés.
Imaginez maintenant le schéma de ces relations. En particulier, imaginez la distance entre ces relations de nœud à nœud. Parce que c’est tout ce que les mathématiques ont à offrir dans ces calculs d’algèbre matricielle… différentes façons de mesurer la distance et la centralité d’une relation dynamique de nœud à nœud et d’un n-gramme à un autre.
Je sais… c’est encore un peu diffus et difficile à comprendre.
Ce qu’il faut retenir, c’est qu’il s’agit d’une grande matrice de données sur les relations ou les connexions entre les nœuds. C’est la chose que nous voulons analyser avec l’algèbre matriciel.
Nous voulons mesurer deux aspects de ce schéma de relations entre les nœuds : l’attention et la cohésion.
Je vais vous montrer des exemples des deux dans un espace bidimensionnel, mais gardez à l’esprit que ce que nous faisons maintenant, c’est appliquer ces visualisations bidimensionnelles sur une matrice de données multidimensionnelle, parce que les mathématiques ne sont pas forcées de voir uniquement en deux ou trois dimensions comme nous le faisons.
L'attention est la persistance ou la prévalence d'une sous-structure narrative par rapport à toutes les autres sous-structures narratives au sein d'une structure narrative plus large.
En anglais, il s’agit d’une mesure de la quantité de battements de tambour des médias financiers sur, disons, « China Tariffs » par rapport à tous les autres battements de tambour des médias financiers qui se produisent sur une période donnée.

Ce n’est pas une carte narrative des « China Tariffs » en février. Il s’agit d’une carte narrative de tous les médias financiers en février. Il ne s’agit pas non plus d’une carte où nous avons simplement mis en évidence le groupe spécifique de nœuds des « China Tariffs », car ce groupe unique est le produit de l' »aplatissement » de la matrice de données multidimensionnelle sous-jacente en une représentation bidimensionnelle des relations de données les plus importantes. C’est une carte de tous les médias financiers en février, où nous avons mis en évidence tous les nœuds qui possèdent une connexion n-gramme pertinente avec la sous-structure narrative de « China Tariffs ».
Si vous êtes familier avec la microscopie ou l’imagerie médicale, la méthodologie utilisée ici est similaire à la « coloration » des cellules qui possèdent un marqueur biologique particulier, indépendamment de l’endroit où ces cellules vivent dans le corps ou sont regroupées sur la lame du microscope. Dans un sens très réel, tout ce que nous voulons étudier est comme un cancer, et nous essayons de mesurer ses métastases dans le temps.
La cohésion est la connexion et la similarité du langage dans une carte narrative, par rapport à lui-même au fil du temps.
En anglais, c’est une mesure de la concentration des médias financiers sur, disons, « l’inflation » ou « Brexit » au fil du temps. C’est une mesure de la signification partagée et de la centralité du sens dans un sujet donné. Par exemple, les deux cartes de droite sont beaucoup plus cohérentes que leurs cousines de gauche :

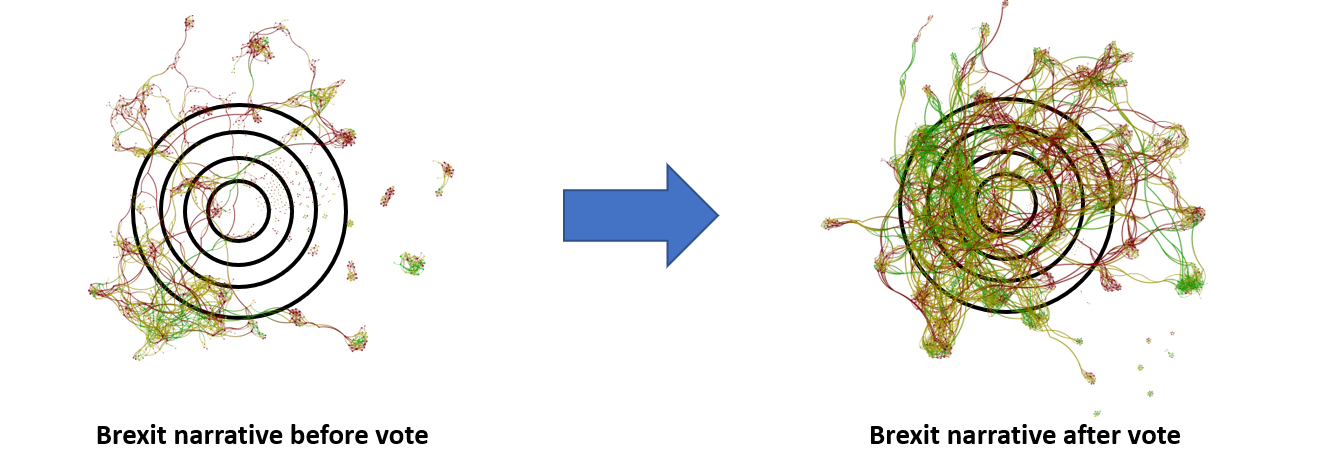
J’aime à penser que la cohésion est une mesure de la distance moyenne entre un nœud et le centre de gravité de la carte globale. C’est la différence entre les gens qui écrivent sur l’inflation ou le Brexit comme un texte jetable, comme quelque chose de marginal par rapport à ce qu’ils écrivent vraiment, et ceux qui écrivent vraiment sur l’inflation ou le Brexit.
Remarquez ce dont nous n’avons pas du tout parlé dans cette discussion sur la façon de mesurer le récit. Nous n’avons pas parlé du sentiment, même si c’est le seul sens que la plupart des gens donnent au concept de récit !
Si vous pensez que vous analysez les récits en mesurant le sentiment, vous vous trompez.
Pourquoi ? Parce que le sentiment est une propriété de chaque nœud individuel. Il n’a rien à voir avec les relations ou les connexions entre les nœuds. Le sentiment est un conditionneur du récit, pas une composante structurelle du récit.
Le sentiment est mesuré en comparant les n-grammes d’un document textuel donné à un lexique de n-grammes qui ont été pré-corrigés pour leur niveau d’affect sentimental. Non seulement cela crée des bizarreries basées sur la façon dont ce lexique a été construit et noté – par exemple, la plupart des lexiques noteraient « surpoids » comme un n-gramme très négatif, même si c’est un n-gramme très positif dans les médias financiers, mais surtout il n’y a pas de comparaison d’un document à un autre. Le sentiment n’est qu’un score indépendant pour ce document particulier. Vous pouvez l’additionner pour obtenir le sentiment moyen de la carte narrative, mais pris isolément, le sentiment va toujours traiter chaque nœud comme étant d’égale importance, indépendamment de sa pertinence pour l’attention et la cohésion de la narration.
Le sentiment est-il une mesure importante ? Bien sûr, mais il n’a de sens pratique, selon nous, qu’en relation avec un élément structurel du récit, comme l’attention ou la cohésion. En fin de compte : le sentiment colore le récit, littéralement dans nos cartes, mais il n’est pas le récit lui-même.
Y a-t-il d’autres aspects des n-grammes qui colorent la narration mais ne sont pas les narratifs en eux-mêmes ? Oui. En particulier, nous pensons qu’il y a une certaine liberté dans le choix des mots, notamment dans les médias financiers et politiques, où les auteurs choisissent intentionnellement un ensemble de mots plutôt qu’un autre afin de présenter leurs opinions comme des faits. C’est ce que nous avons appelé Fiat News, et nous sommes en train de développer notre propre lexique pour ce conditionneur de récit.
C’est donc ainsi que nous mesurons les récits du marché de manière rigoureuse.
Il nous faut maintenant relier ces mesures à une théorie des flux monétaires.
C’est un lien assez élémentaire, vraiment, et c’est au cœur de toute la publicité … en fait, de tout le marketing depuis l’aube des temps : nous n’achetons pas ce que nous ne remarquons pas.
C’est aussi vrai pour les actions des grandes sociétés que pour le savon ou les cornflakes, et Wall Street le sait. La façon d’anticiper les flux financiers est de suivre l’effort que fait Wall Street pour vous faire remarquer tel ou tel secteur. Cet effort est ce que nous appelons la narration, et plus l’effort est important, plus nous le remarquons. Plus nous le remarquons, plus nous sommes susceptibles d’acheter, en particulier si cet effort est associé à un discours ciblé et à une orientation positive.
En suivant l’effort narratif, la concentration et l’inclinaison – ou ce que nous appelons l’attention, la cohésion et le sentiment – nous pensons pouvoir anticiper les flux d’argent. Nous pensons que différentes combinaisons d’attention, de cohésion et de sentiment plus ou moins élevées que d’habitude créent différentes pressions sur les futurs flux financiers. Ce qui signifie des pressions différentes sur les prix futurs.
Nous avons théorisé quatre combinaisons de base – ce que nous appellerons des Régimes Narratifs – qui, selon nous, créent une pression sur les flux monétaires futurs. Il y en a sans doute d’autres.
Les Premiers Battements de Tambours : Attention faible + Sentiment élevé Marché haussier Hésitant : Faible Cohésion + fort Sentiment Marché baissier Cohérent : forte Cohésion + faible Sentiment Sur-acheté : Haute Attention
Et nous pensons qu’ils fonctionnent ainsi :
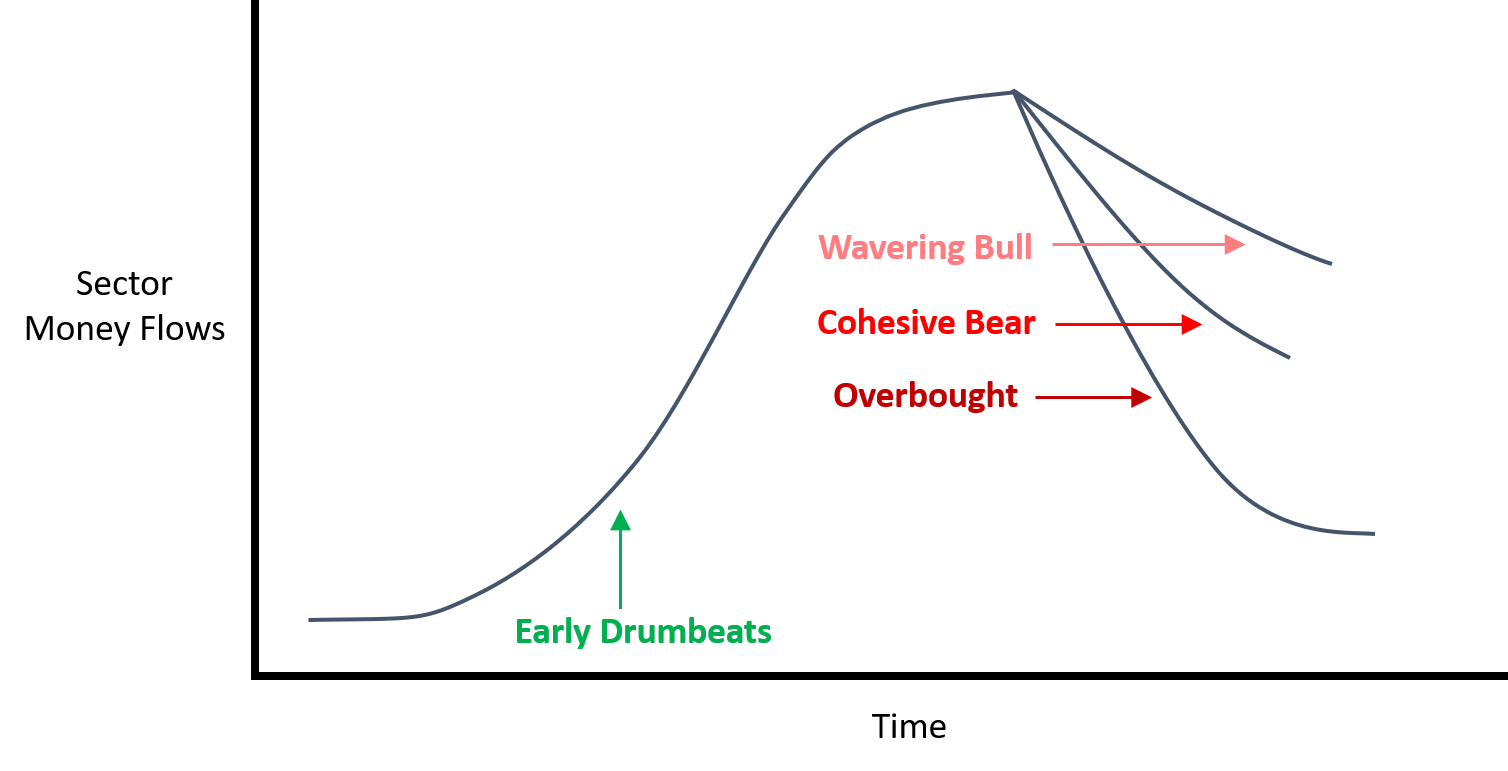
Tout narratif de marché a un cycle de vie.
Il naît, il grandit, il se reproduit peut-être, et il meurt.
La naissance d’un narratif de marché prend souvent la forme des « Premiers Battements de Tambours ». Ici, le score d’attention est faible, mais le sentiment est élevé. Wall Street doit essayer différents arguments, différents récits avant de trouver celui qui lui convient. Mais ils trouveront celui qui tient la route, et le résultat est l’attention des investisseurs. Les investisseurs remarquent le secteur. Les investisseurs entendent l’effort de marketing. Et les investisseurs achètent. Pouvez-vous mesurer les « Premiers Battements de Tambours » au temps T ? Il faut alors posséder le secteur au temps T+1, car c’est à ce moment que l’argent afflue vraiment.
Toutes les bonnes choses ont une fin. Peut-être que Wall Street réussit tellement bien à créer un récit de marché convaincant que l’attention devient inhabituellement élevée (Sur-achat). Mesurez cela au temps T ? Vous voudrez vendre ce secteur au temps T+1. Ou peut-être que le récit du marché perd son intérêt tout en gardant une orientation positive – Marché haussier hésitant. C’est ainsi qu’un récit meurt lentement. Ou peut-être que le récit du marché reste centré sur le secteur mais s’aigrit – Marché baissier cohérent. Cela arrive plus souvent que vous ne le pensez, surtout après une longue période de battements de tambour positifs qui n’ont pas vraiment abouti. Vous verrez aussi des ventes quand ce régime narratif s’installera.
Ces derniers mois, nous avons fait tourner des processeurs et des tâches 24 heures sur 24 et 7 jours sur 7 pour calculer les scores d’attention, de cohésion et de sentiment pour les onze secteurs du S&P 500, afin de pouvoir tester ces théories narratives des flux monétaires. C’est une énorme quantité d’analyses informatiques qui nous a permis d’obtenir … 24 mois de données jusqu’à présent.
Honnêtement, je ne sais pas où tout cela va finir.
Honnêtement, je ne sais pas comment vous parler de nos résultats préliminaires sans vous raconter une histoire sur nos résultats préliminaires, car c’est ce que sont les résultats préliminaires… une histoire. Et si vous avez suivi un tant soit peu la théorie d’Epsilon, vous saurez ce que je veux dire quand je dis que c’est une très mauvaise façon de jouer à ce méta-jeu.
Je ne parlerai donc pas de résultats tant que je ne pourrai pas le faire sans raconter une histoire, tant que je ne pourrai pas vous montrer des résultats qui parlent d’eux-mêmes. C’est comme la différence entre les cartes narratives interprétées qualitativement et les calculs algébriques sur la matrice de données sous-jacente… la différence entre ce que nous pensons et ce que nous pouvons mesurer.
Mais je continuerai à parler de notre programme de recherche, rarement de façon claire avec des notes comme celle-ci, mais ouvertement et pleinement avec nos abonnés d’Epsilon Theory Professional.
Ben Hunt
Traduit par Michel, relu par jj pour Le Saker Francophone