
Accélérer la collecte de données historiques
Par Peter Turchin − Le 22 novembre 2025 − Source Cliodynamica

Seshat : Global History Databank recueille systématiquement les connaissances actuelles sur l’organisation sociale et politique des sociétés humaines et sur l’évolution des civilisations au fil du temps.
Dès le lancement de Seshat en 2011, nous avons commencé à réfléchir à la manière d’accélérer la collecte de données en l’automatisant (ou même en la semi-automatisant). Mais à l’époque, la technologie n’était tout simplement pas assez sophistiquée. Nous avons essayé différentes approches, mais elles exigeaient toutes plus d’efforts que la simple collecte manuelle des données.
Gardez à l’esprit que la collecte de données pour Seshat est une opération assez sophistiquée. Au cours des premières années, nous avons essayé différentes approches. Nous avons constaté que demander à des universitaires de coder les données relatives aux sociétés dont ils sont experts ne fonctionne pas : cela représente beaucoup de travail et ce sont des personnes très occupées. Le recours à des étudiants était encore pire : il fallait plus de temps et d’efforts pour les former (et les perdre peu après) que pour collecter les données soi-même. Peu à peu, nous avons mis au point une approche qui repose sur une combinaison de chercheurs de longue date (certains travaillent pour Seshat depuis plus de 10 ans) titulaires d’une maîtrise ou même d’un doctorat, de spécialistes en sciences sociales et d’experts dans le domaine. Si vous souhaitez en savoir plus, vous pouvez consulter l’article The Equinox 2020 Seshat Data Release ou la section « Méthodes » de cet article : Expliquer la montée des religions moralisatrices : un test d’hypothèses concurrentes à l’aide de la base de données Seshat.
Le point essentiel est que le codage des données historiques pour les variables Seshat est une tâche cognitive très exigeante, et les versions précédentes de l’intelligence artificielle (IA) n’étaient tout simplement pas à la hauteur. Nous avons régulièrement essayé les derniers LLM (modèles linguistiques à grande échelle) disponibles à l’époque, mais les résultats étaient lamentables. Les LLM hallucinaient à tout va. Même lorsqu’ils arrivaient à une réponse raisonnable, ils inventaient des citations (toutes les données Seshat doivent être étayées par une source académique ou une communication personnelle d’un expert universitaire). Nous avons donc continué à collecter des données manuellement.
Puis, il y a environ un an, tout a changé. Je me souviens qu’après avoir lu des articles sur DeepSeek, je l’ai testé pour ses connaissances historiques et j’ai été impressionné. La nouvelle génération de LLM était d’un ordre de grandeur supérieur à celle de l’année précédente. Il s’agissait d’un bond qualitatif. Ces modèles d’IA comprennent non seulement DeepSeek, mais aussi ChatGPT, Gemini et d’autres.
En janvier de cette année, nous avons décidé de nous intéresser sérieusement à cette nouvelle technologie. Nous devions développer Seshat en ajoutant deux types de données : l’instabilité politique et les résultats des fouilles et des enquêtes archéologiques. Dans cet article, je vais parler des données sur l’instabilité, qui sont à un stade plus avancé, et je reviendrai plus tard sur les données archéologiques.
L’approche que nous avons développée pour quantifier l’instabilité repose sur le recensement des événements de violence politique, allant des micro-événements, tels que les assassinats politiques ou les émeutes urbaines dans lesquels une ou quelques personnes sont tuées, aux macro-événements, tels que les guerres civiles à grande échelle et les révolutions transformatrices qui tuent des milliers, voire des millions de personnes. Cette approche, à ma connaissance, a été mise au point par le sociologue russo-américain Pitirim Sorokin.

Au cours de la préparation de son ouvrage en plusieurs volumes intitulé Social and Cultural Dynamics (1937-1941), Sorokin a écrit à plusieurs de ses amis historiens pour leur demander de dresser une liste des événements d’instabilité dans une société historique dont ils étaient experts. Il leur a également demandé de les quantifier selon plusieurs dimensions : domaine social, durée, masses impliquées et intensité (violence et effets).
À partir de ces données, Sorokin a produit une série de courbes documentant les fluctuations de l’instabilité dans diverses sociétés historiques. Voici, par exemple, son graphique pour la Rome antique :
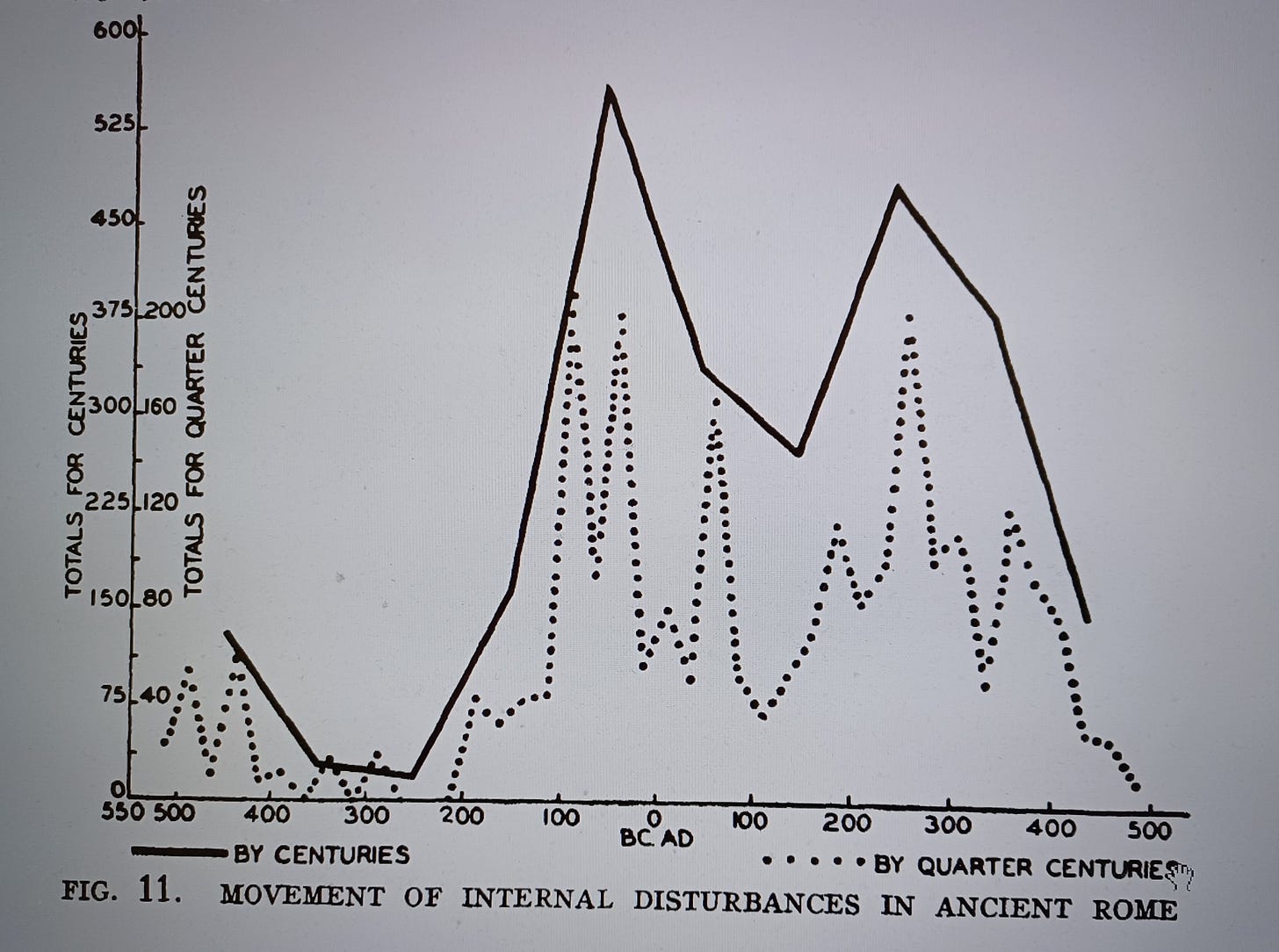
J’ai pris connaissance de ces travaux de Sorokin et de ses collaborateurs peu après être passé de l’écologie à la cliodynamique à la fin des années 1990. Puis, à la suite de ma prédiction de 2010 concernant l’instabilité croissante en Amérique et en Europe occidentale, j’ai décidé que j’avais besoin de données similaires pour les États-Unis. À l’époque, je ne pouvais pas utiliser l’IA (car elle n’était pas à la hauteur de la tâche) ni faire appel à des chercheurs humains (car je n’avais pas les fonds nécessaires pour les engager), alors je l’ai fait moi-même. J’ai passé tout l’été à rechercher dans les archives des journaux américains et à saisir les données à la main dans une base de données. Ce fut l’un des étés les plus misérables de ma vie, car il était incroyablement déprimant de lire les détails horribles de divers événements violents : lynchages, affrontements raciaux et ethniques violents, répression de rébellions, etc.

Ces données ont été publiées dans mon article de 2012 dans le Journal of Peace Research, Dynamique de l’instabilité politique aux États-Unis, 1780–2010.
Plus récemment, l’ensemble de données a été mis à jour jusqu’en 2024 par mes assistants de recherche et j’en parlerai dans un prochain article de la série Structural-Demographic State of America.
OK, jusqu’en 2024, nous avons collecté les données Seshat manuellement, avec un minimum d’automatisation (principalement la possibilité de rechercher dans des PDF). Et, comme je l’ai dit au début de cet article, tout a changé en 2025. Mais il n’y avait pas de solution magique permettant aux LLM de prendre complètement le relais de la collecte de données. Comme tout le monde le sait, on ne peut pas faire confiance à l’IA, même aux modèles avancés actuels. Nous avons en fait suivi un processus assez intense pour apprendre à utiliser efficacement les LLM. Les prochains articles de cette série, rédigés par les membres de notre projet, vous donneront des détails sur la manière dont nous nous répartissons les différentes tâches ; en voici un aperçu.
Notre approche actuelle ressemble à un sandwich, avec une couche de viande entre deux tranches de pain. La « viande » correspond aux données générées par les LLM, tandis que le « pain » fait référence aux contributions humaines.
La première phase de la collecte de données consiste à concevoir une requête efficace pour une génération optimale des données. Nous avons effectué trois itérations majeures de ce processus, qui ont généré les lots de données 1, 2 et 3. Nous travaillons actuellement sur le lot 3, mais il est également clair que nous pouvons encore l’améliorer. Je pense donc qu’à l’avenir, nous aurons des lots 4, 5, … notamment parce que les LLM s’améliorent constamment.
La deuxième phase consiste à exécuter les LLM afin de générer des données sur les événements d’instabilité pour de nombreuses entités politiques. Le lot 3 contient 9711 événements pour 571 entités politiques.
La troisième phase consiste à faire vérifier les données générées par les LLM par des chercheurs humains. Jusqu’à présent, nous avons vérifié 1 100 événements, soit un peu plus de 10 %.
La quatrième phase consiste en des vérifications par des experts du domaine (d’accord, c’est un sandwich à deux étages). Jusqu’à présent, quatre historiens spécialisés dans Byzance, dans plusieurs empires islamiques et dans l’Empire allemand (alias le Saint-Empire romain germanique) ont examiné les données générées par les LLM. La quatrième phase est celle qui prendra le plus de temps et qui, très probablement, ne sera jamais terminée. Mais l’objectif n’est pas de faire vérifier les données de chaque événement par des historiens. Tenter de créer une base de données dans laquelle chaque donnée est « correcte » est un objectif irréalisable : toutes les grandes bases de données contiennent divers types d’erreurs. Nous avons plutôt besoin de ces vérifications par des experts pour estimer la précision des données obtenues (ce qui est utile à savoir au stade de l’analyse) et déterminer comment améliorer leur précision dans les itérations futures.
Mes collègues fourniront plus de détails dans des articles ultérieurs, mais voici une évaluation préliminaire. Les LLM continuent de produire des hallucinations, mais la fréquence des « données » erronées a considérablement diminué par rapport à il y a un an. Il est intéressant de noter que les hallucinations les plus fréquentes concernent les numéros de page (nous demandons aux LLM de fournir une source académique — un article ou un livre — et le numéro de page d’où les données sont extraites). Parfois, les LLM nous donnent également de fausses références ou mélangent les choses (par exemple, en nous donnant le titre d’une publication réelle, mais l’auteur d’une autre publication réelle). Dans l’ensemble, environ 17 % des entrées générées par les LLM présentent actuellement des problèmes de références.
D’autres problèmes, plus rares, concernent des événements qui ne se sont jamais produits, des événements comptés deux fois (doublons) et des estimations erronées des caractéristiques quantitatives que nous demandons aux LLM de coder (étendue géographique et intensité, qui reflète le nombre de personnes tuées). Dans l’ensemble, actuellement, seule la moitié des événements générés par les LLM sont entièrement corrects ou ne nécessitent que des modifications mineures. Comme on pouvait s’y attendre, la probabilité d’erreurs augmente à mesure que l’on remonte dans le temps et que l’on s’éloigne de l’Europe.
Malgré cela, la vitesse à laquelle nous sommes désormais capables de collecter des données est d’un ordre de grandeur supérieur à celle que nous aurions sans les LLM. Il est tout simplement beaucoup plus rapide de vérifier et de corriger les erreurs dans les résultats générés par les LLM que de collecter des données à partir de zéro. Par exemple, un numéro de page erroné est rapidement corrigé par le vérificateur qui recherche le nom d’un événement dans le PDF source.
Il y aurait beaucoup plus à dire sur ce sujet, mais je m’arrêterai là et laisserai mes collègues fournir plus de détails dans les prochains articles.
Peter Turchin
Traduit par Hervé, relu par Wayan, pour le Saker Francophone